|
In a discussion with Jaroslav Suchanek from Czechia a slightly different problem arose. Not so much the import / export of the characters with diacritics but other symbol-like elements in RTF such as 'bullet' and 'endash', 'emdash' that have a RTF-typical encoding. In order to tackle this problem one should get back to the basics. The TOS operating system [or enhancements] let you have a mapping between the keycode and the 0-255 range. Pascal Fellerich's programme allows you to make such mapping - I have the numerical pad redesigned for the Polish ogonki - but also MagiC/Jinnee has a similar option [using a German MagiC I had to change the Y/Z into Z/Y a.o.]. This is great when you're using fonts [with up to 256 characters], you can decide exactly what you need under what key you want [within the 0-255 range of course]. Working with Calamus SL I don't need NVDI and still have the ogonki within reach. Working with NVDI however you have to tell NVDI which character has to be mapped and how into the 0-255 range. That's when SPDCHAR.MAP comes in. Through this mapping table you can redirect a [limited] number of character from a 0-653 range to the 0-255 range. It works with the Bitststream Speedo fonts but also with [most] modern TrueType fonts. I haven't seen any PostScript Type 1 however that has such properties! |
Zoals al eerder is gezegd kan Papyrus niet echt omgaan met *.doc files van MS-Word maar wel met de *.RTF files zoals door MS-Word geproduceerd. Het RTF ofwel Rich Text Format is een echte ASCII-file d.w.z. alle tekens boven de 128 zijn gecodeerd als '\ xx' met xx de hexadecimale vorm van het getal boven de 128. Om te kunnen weten welke 'codepage' van toepassing is voor het interpreteren van deze notaties is bovenaan in de RTF-file een 'ansicpg' aangegeven [ANSI codepage]. Papyrus kan in princpe aan de hand hiervan automatische de juiste [codepage ]filter kiezen, maar in de praktijk werktt dat niet en kun je hem beter zelf instellen op de goede filter. Vervolgens wordt door Papyrus de hele opmaak van de RTF-file goed overgenomen. Een apart probleem vormen de tekens die niet zo zeer met behulp van een filter kunnen worden geim/ëxporteerd zoals 'bullet', 'emdash', 'endash' waarvoor RTF een aparte notatie heeft. Bij import vanuit een RTF-file worden \bullet \endash \emdash netjes overgezet naar de juiste tekens [ze hebben als Unicode coderingen: U+2022, U +2013, U+2014]. Bij export terug naar een RTF-file krijgt alleen de 'bullet' de goede RTF-notatie: \bullet, de beide andere worden als leesbare tekens afgebeeld: brede en smalle streepjes. Met andere woorden je krijgt de \emdash en \endash niet terug. |
|
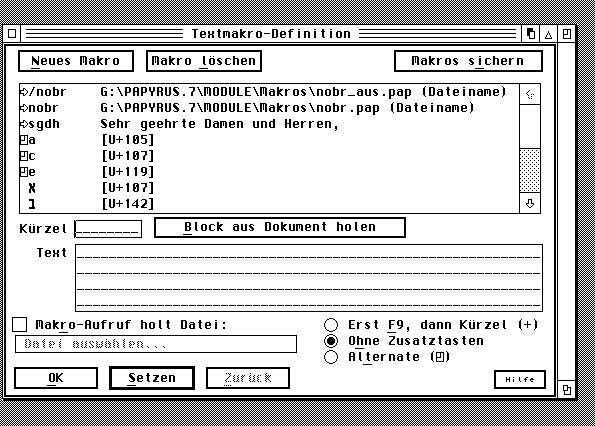
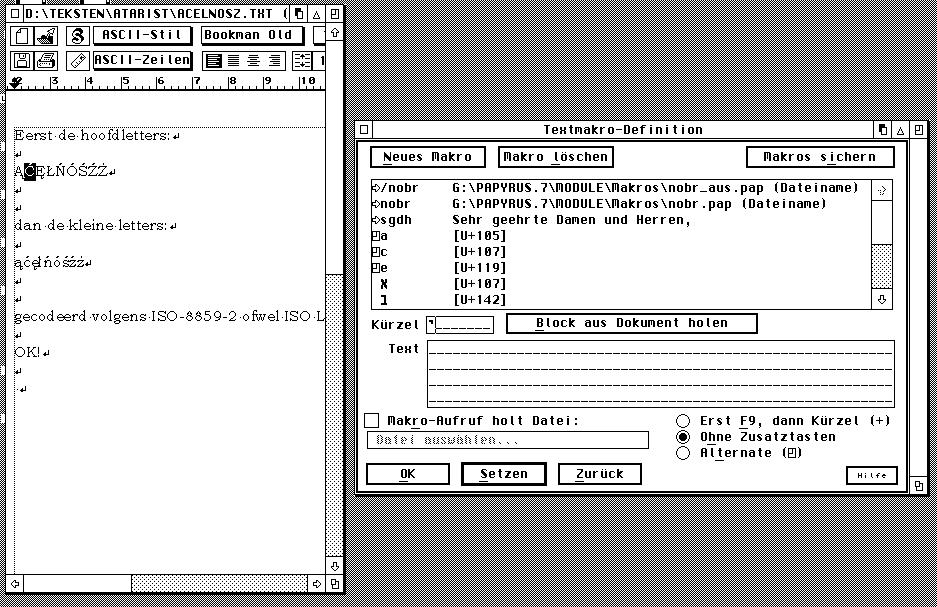
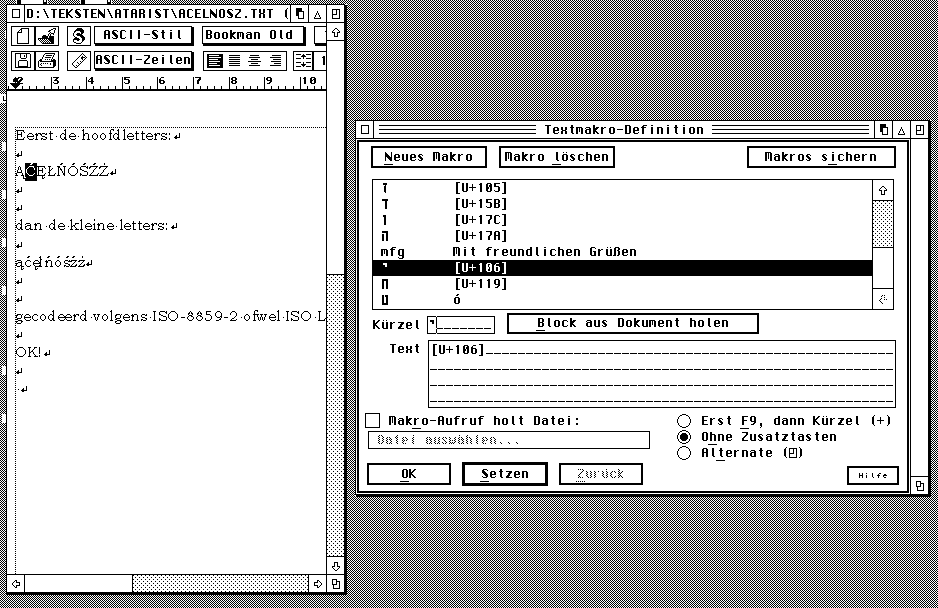
When using Papyrus you can forget about the SPDCHAR.MAP enhancement since Papyrus allows you to use the 'complete' Unicode range. Make sure that the 'compatibility' under 'options' is not for the 'Atari Belegung' but points to Unicode 'Erweitert'. When importing texts you have to make sure the right import-filter [in the Belegung folder] is chosen and if that one doesn't suit you you can edit one yourself. The same goes for the export-filter you need. But all filters still depend on some sort of 0-255 range since the big bad world is still not ready for 2-bytes solutions ;) Within Papyrus you can assign any key combination to a particular character by using the 'macro' option. Make a small text window wherein you insert all the characters you need from the large Unicode character-table [that may include bullets, haceks whatever]. While defining the 'macro' keep the desired character selected and use 'Block holen', in the 'kurzel' you put the 'key[-combination]' you want. As far as I understand it there is a fixed relation now between the 'keycode' and the 'U+....' as defined in your 'macro'. This suggestion was made available during a discussion in a Polish newsgroup and was handed out by Konrad Kokoskiewicz . |
Jaroslav Suchanek uit Tsjechië die met dit probleem kwam had ook nog het probleem van de Tsjechische lettertekens die prima overkwamen [vanuit MS-Word] naar Papyrus onder gebruik van het juiste ISO-8859-2 filter maar zich afvroeg wat te doen als hij de tekst moest verbeteren en weer terug zetten in RTF-formaat. De complicatie zit hem erin dat bij import uit MS-Word de 'Atari-Belegung' in Papyrus is afgezet en de SPDCHAR.map voor NVDI niet meer actief is. Het gedefinieerd hebben van de Tsjechische [of Poolse] letters onder bepaalde toetsen kan met behulp van Pascal Fellerich's Compose maar dat werkt dan niet meer. Hoe toets je nu dan wel je letters met diacritische [accenten e.d.] tekens in? De oplossing die eigenlijk heel simpel is werd gegeven door Konrad Kokoskiewicz [http://www.orient.uw.edu.pl/ conradus/atarieng.htm]) die tijdens een discussie van een Poolse nieuwsgroep uitlegde dat het mogelijk is om binnen Papyrus een macro te definiëren. Wat je moet doen is eerst een kleine tekst-file in Papyrus te schrijven waarin je alle te gebruiken lettertekens inbrengt met behulp van het overzicht van de grote Unicode letterbak [klik op een teken daaruit en ze wordt overgenomen in je tekst, dit 100-en keren doen is te omslachtig, maar eenmalig moet geen probleem zijn!]. In deze tekst-file zet je alle ogoneks, haceks, maar ook bullets etc. Tijdens het definiëren van de macro wordt het teken in je tekst geselecteerd gehouden, en binnen het macro-venster met 'Block holen' opgepakt. In 'kurzel' komt de gewenste toets[en-combinatie]. Vervolgens verschijnt in het macro-venster de 'U+....' code van het betreffende teken. |
|
|
|
So far this should allow you to write any character you want - but still within Papyrus - and using the keys or key-combinations you want. The big problem arises when you have to get back to RTF [or ASCII or HTML]. I tried to have Papyrus import the \bullet \endash \emdash inserted in a RTF-file. It produces the right characters [ U+2022, U +2013, U+2014 ] on screen but after exporting only U+2022 gets a RTF-notation: \bullet , the other two remain visible characters. Exporting daggers [U+2020, U+2021] results in [U+2020] and [U+2021] in the RTF-files. It looks like you have to experiment a bit: use a different editor - I used QED - to insert RTF-notations and see what Papyrus produces on screen and then export the text ['Erzeugen - RTF']. To have Papyrus export a proper \endash, \emdash and the like things should be discussed with Christian Nieber] [of R.O.M. Logicware]. |
Papyrus allows the HTML-4 import using Ź like notations, the RTF-export of such file results in notations usch as \' ba [the position in the 0-255 range according to the given codepage - here ISO88592]. The '377' refers to the ISO10646/Unicode table directly. Papyrus did recognize the • [bullet] though. This new - HTML-4 - notation frees us of the limited range of [ISO Latin 1 based] notations such as: ñ ä that are of no use to Eastern European users a.o. [ &endash; &emdash; might be useful to you though] You can find such HTML-files originating from M$ Office 97 so re-importing such files into M$Word should be no problem. Only Papyrus can handle these HTML-files, CAB 2.6 can't. |