|
Zoals al eerder is gezegd kan Papyrus niet echt goed omgaan met *.doc files van MS-Word maar wel met de *.RTF files zoals door MS-Word geproduceerd. Het RTF ofwel Rich Text Format is een echte ASCII-file d.w.z. alle tekens boven de 128 zijn gecodeerd als '\ xx' met xx de hexadecimale vorm van het getal boven de 128. Om te kunnen weten welke 'codepage' van toepassing is voor het interpreteren van deze notaties is bovenaan in de RTF-file een 'ansicpg' aangegeven [ANSI codepage]. Papyrus kan in princpe aan de hand hiervan automatische de juiste [codepage ]filter kiezen, maar in de praktijk werktt dat niet en kun je hem beter zelf instellen op de goede filter. Vervolgens wordt door Papyrus de hele opmaak van de RTF-file goed overgenomen. |
Een apart probleem vormen de tekens die niet zo zeer met behulp van een filter kunnen worden geim/exporteerd zoals 'bullet', 'emdash', 'endash' waarvoor RTF een aparte notatie heeft. Bij import vanuit een RTF-file worden \bullet \endash \emdash netjes overgezet naar de juiste tekens [ze hebben als Unicode coderingen: U+2022, U +2013, U+2014]. Bij export terug naar een RTF-file krijgt alleen de 'bullet' de goede RTF-notatie: \bullet, de beide andere worden als leesbare tekens afgebeeld: brede en smalle streepjes. Met andere woorden je krijgt de \emdash en \endash niet terug. Jaroslav Suchanek uit Tsjechië die met dit probleem kwam had ook nog het probleem van de Tsjechische lettertekens die prima overkwamen [vanuit MS-Word] naar Papyrus onder gebruik van het juiste ISO-8859-2 filter maar zich afvroeg wat te doen als hij de tekst moest verbeteren en weer terug zetten in RTF-formaat. De complicatie zit hem erin dat bij import uit MS-Word de 'Atari-Belegung' in Papyrus is afgezet en de SPDCHAR.map voor NVDI niet meer actief is. Het gedefinieerd hebben van de Tsjechische [of Poolse] letters onder bepaalde toetsen kan met behulp van Pascal Fellerich's Compose maar dat werkt dan niet meer. Hoe toets je nu dan wel je letters met diacritische [accenten e.d.] tekens in? |
|
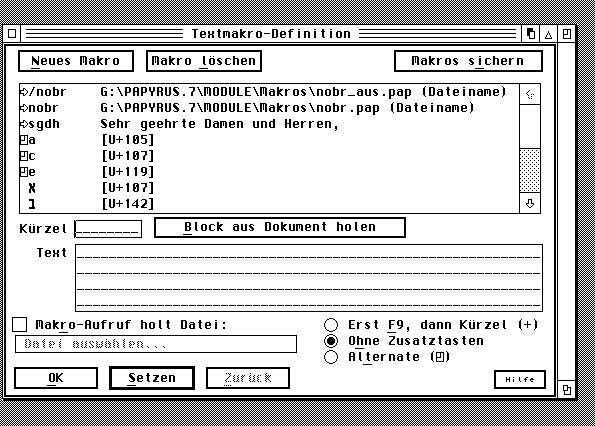
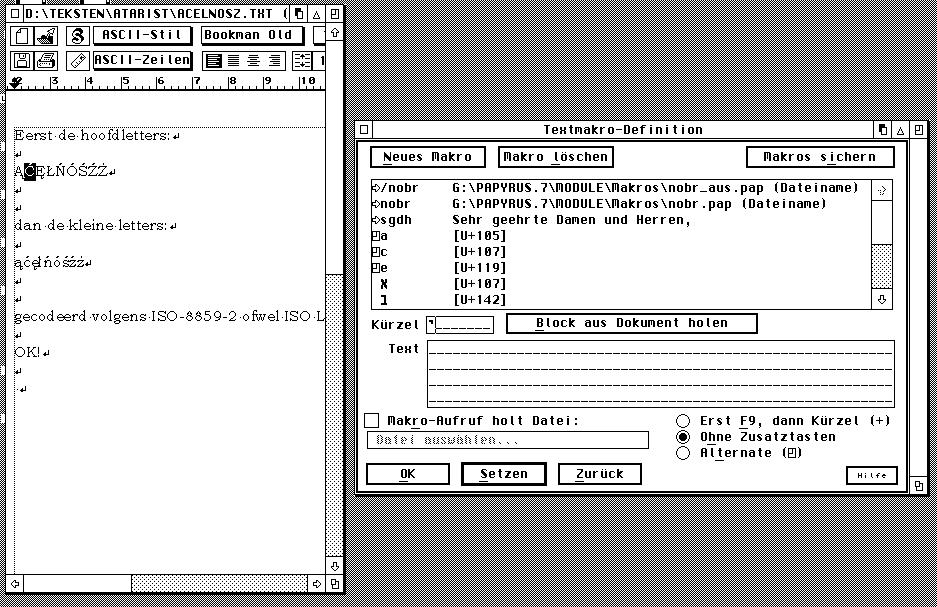
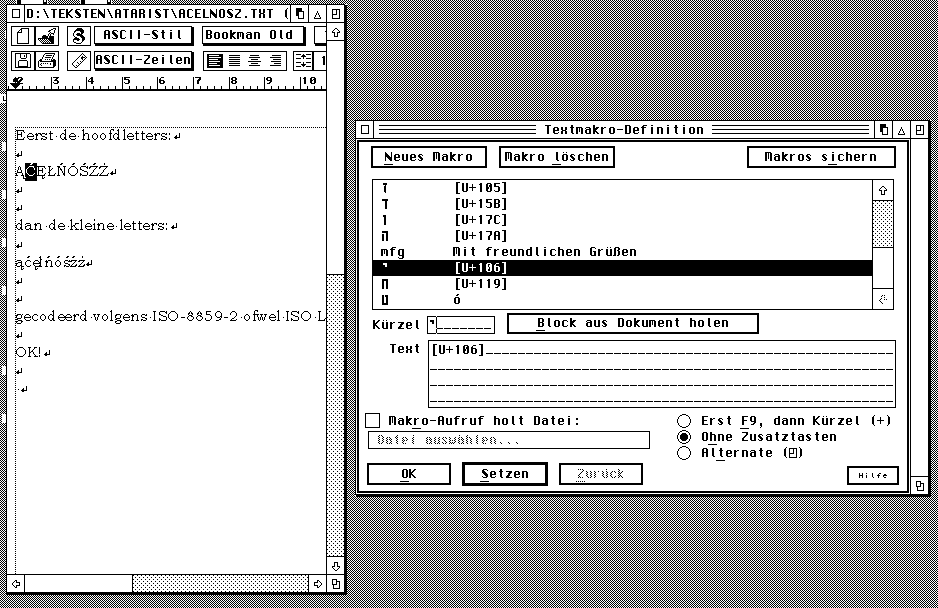
De oplossing die eigenlijk heel simpel is werd gegeven door Konrad Kokoskiewicz die tijdens een discussie van een Poolse nieuwsgroep uitlegde dat het mogelijk is om binnen Papyrus een macro te definiëren. Wat je moet doen is eerst een kleine tekst-file in Papyrus te schrijven waarin je alle te gebruiken lettertekens inbrengt met behulp van het overzicht van de grote Unicode letterbak [klik op een teken daaruit en ze wordt overgenomen in je tekst, dit 100-en keren doen is te omslachtig, maar eenmalig moet geen probleem zijn!]. In deze tekst-file zet je alle ogoneks, haceks, maar ook bullets etc. Tijdens het definiëren van de macro wordt het teken in je tekst geselecteerd gehouden, en binnen het macro-venster met 'Block holen' opgepakt. In 'kurzel' komt de gewenste toets[en-combinatie]. Vervolgens verschijnt in het macro-venster de 'U+....' code van het betreffende teken.
Papyrus is nogal eigenwijs als het gaat om HTML-bestanden, ook al zijn die voorzien van een characterset aangegeven met ISO-8859-8 [Hebreeuws] dan nog doet Papyrus alsof het om ISO-8859-1 gaat. Via een omweg rolt er nog wel Hebreeuws uit maar dan niet meer als HTML geinterpreteerd!
|